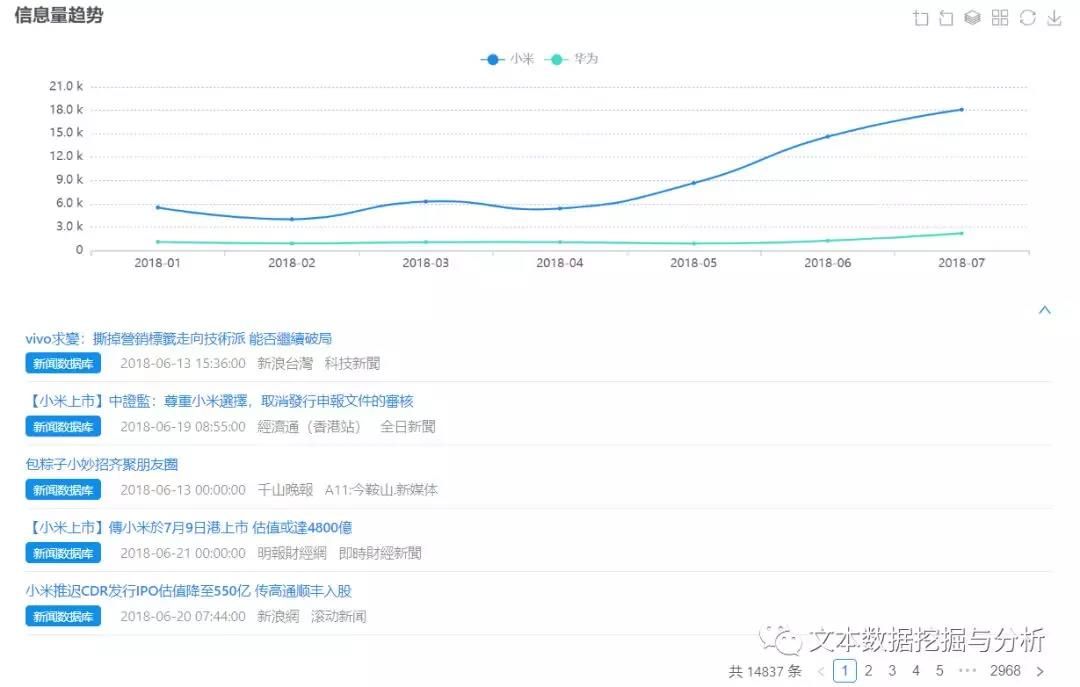
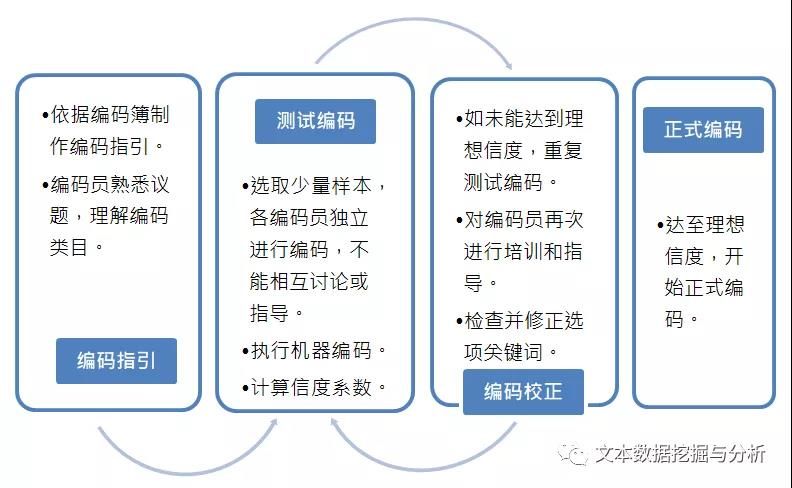
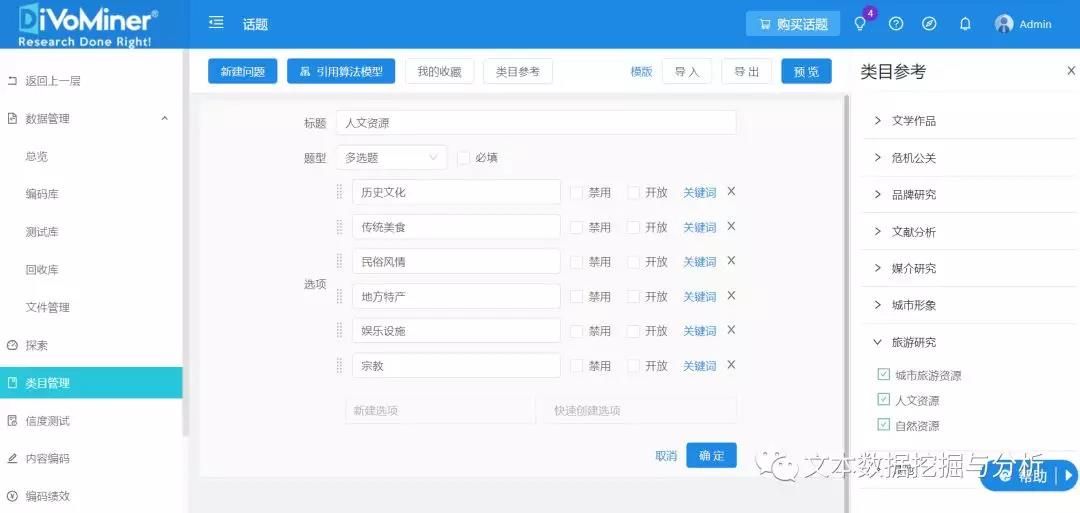
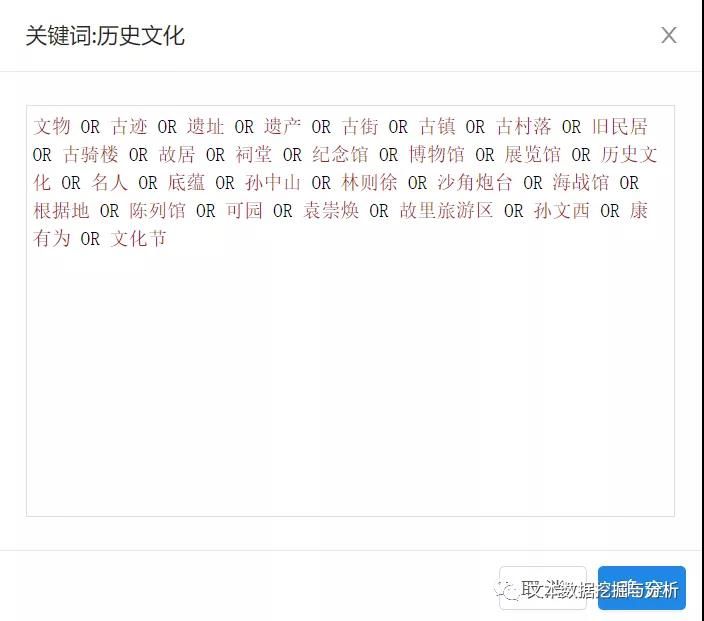
大数据技术辅助在线内容分析法是将传统内容分析的操作流程搬到“线上”,结合大数据技术,用网络挖掘、机器学习、自然语言文本处理等实现文本数据的在线处理,使得内容分析法的全部流程在线一站式完成,大大缩短研究时间,提升研究效率,快速产出研究论文。
大数据技术辅助在线内容分析法为何能快速产出论文呢?这要从在线内容分析法本身的优势谈起。
本文主要阐述在线内容分析法的优势,当我们运用大数据技术辅助在线内容分析法(回顾前文:如何结合机器与人工进行文本数据研究?)做研究时,可以在此基础上阐述大数据技术辅助在线内容分析法的优势。
首先带大家回顾一下
什么是在线内容分析法
(online content analysis)?
(请仔细阅读)
在线内容分析法是分析文本内容的研究方法,是一个旨在识别和描述特定研究学科的总体趋势和研究成果评估系统。[1]包括书籍、章节、采访、讨论、报纸标题和文章、历史资料、演讲、谈话、广告、戏剧、非正式交谈或者任何交流性的语言。整个分析流程是线上完成。
看不太明白再看下面这个概念
(小编自认为这个概念讲得更清楚一些)
在线内容分析法是社会科学研究方法中的一种对文本内容进行编码、分类、语义判断及形成可供统计分析之用的量化分析方法。它是指一种以系统、客观与量化的方式,来研究与分析传播内容,以测量及解读内容的研究方法。[2]
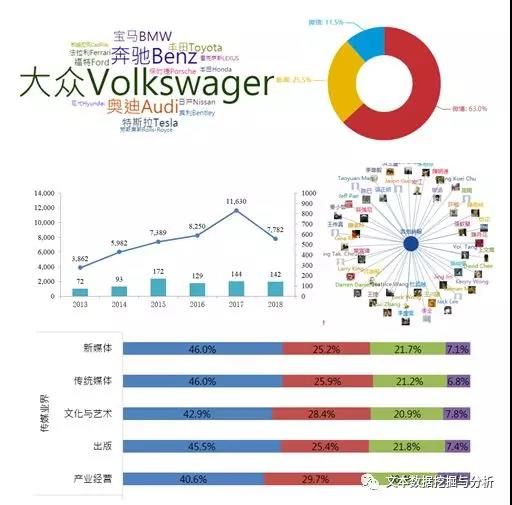
在线内容分析法是一种研究方法,它是系统的、可重复使用的研究方法,用来把杂乱无章的非结构化文本内容转化成结构化的数据,也就是可视化图表,以对内容进行分析、解读,得出深入的推论、洞察,挖掘价值。
操作过程
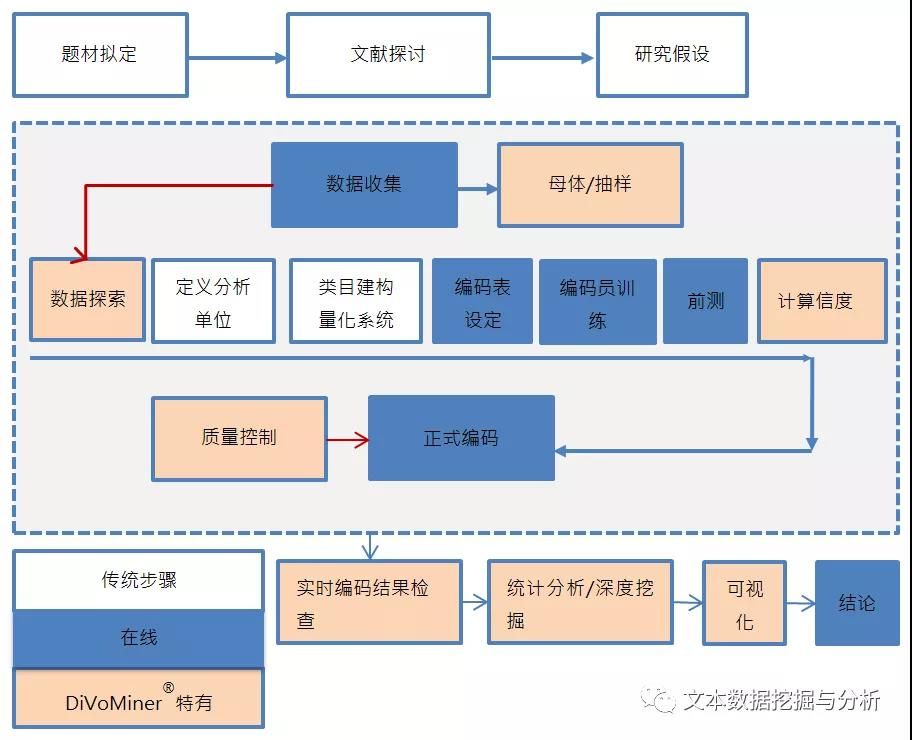
在DiVoMiner 文本大数据挖掘及分析平台(me.divominer.cn)上进行,在确保研究流程科学、严谨方面,这个平台具有完备的质量控制机制,尤其是编码员间的信度计算程式清晰、自带学术界认可的四种信度计算方法,并具有编码追踪功能,可以随时定位编码结果,所有的数据分析结果也可以追踪回溯至原文。(没错,小编就是在强调这个工具的可靠性)
文本大数据挖掘及分析平台(me.divominer.cn)上进行,在确保研究流程科学、严谨方面,这个平台具有完备的质量控制机制,尤其是编码员间的信度计算程式清晰、自带学术界认可的四种信度计算方法,并具有编码追踪功能,可以随时定位编码结果,所有的数据分析结果也可以追踪回溯至原文。(没错,小编就是在强调这个工具的可靠性)
点击文末“阅读原文”或扫描下方二维码快速注册帐号,永久免费使用学习版!

有何优势?
下面内容是我选择在线内容分析法来做研究的原因(内容似乎有那么一些晦涩,如有疑惑欢迎留言和小编讨论沟通,以求甚解,欢迎来撩)
一
研究方法的非介入性
在线内容分析法是社会科学研究方法中唯一一种不受时间和空间限制的方法。相比于其他社会科学研究方法,如控制实验、访谈、焦点小组、问卷调查等,这些测量行为会使得观察者影响研究主体,从而影响测量结果。而在线内容分析法作为一种非反应性或非介入性的研究方法,则避免了观察者对研究对象的影响。
二
保留数据来源的最初概念构想
在线内容分析法可将非结构性资料转化成结构性的数据,因分析是建立在原有数据资料生成之后的,研究者无法完全预知数据来源所使用的类目,因此在线内容分析法可以保留数据来源的概念构想,这是问卷调查和结构性访谈等其他结构性方法所欠缺的。
三
对语境具有敏感性
控制实验、问卷调查和结构性访谈等无法将数据还原至原有语境,而在线内容分析法则承认数据的文本性,对语境具有敏感性。允许研究者针对有意义的或具代表性的数据本身进行处理。
四
可靠且可复制
与所有实证研究一样,在线内容分析法依靠系统和可复制的技术来生成数据进行分析研究,主要在于其可靠性和可复制性,换句话说,如果分析类别和编码方案设计合理,任何人都能够进行分析,[4]因而限制了研究者个人观点对研究结构的影响。
五
可处理大批量文本
区别于民族志方法、历史编撰学方法和诠释研究,这类仅可以对小量文本进行分析研究的方法,而在线内容分析法则因其具明确性的程序和统一的操作性,则可以处理大批量的文本。对于大批量文本的研究分析,这是其他研究方法难以实现的。
参考文献
[1] Calik M, Sozbilir M (2014). İcerik Analizinin Parametreleri, Eğitim ve Bilim, 39(174), 33-38.
[2] Kerlinger, F.N. (1973). Foundations of behavioral research (2nd ed.). New York: Holt, Rinehart & Winston.
[3]张荣显,曹文鸳:《网络舆情研究新路径:大数据技术辅助网络内容挖掘与分析》,《汕头大学学报》(人文社会科学版)2016年,第8期,第111-121页
[4] Neuendorf, K. (2004). Content analysis: A contrast and complement to discourse analysis. Qualitative Methods (newsletter of the APSA Organized Section on Qualitative Methods), 2(1). 33-36.


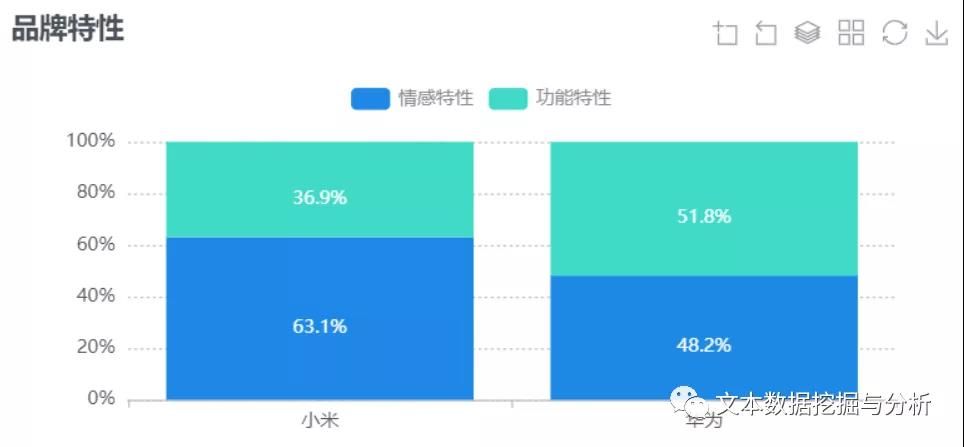
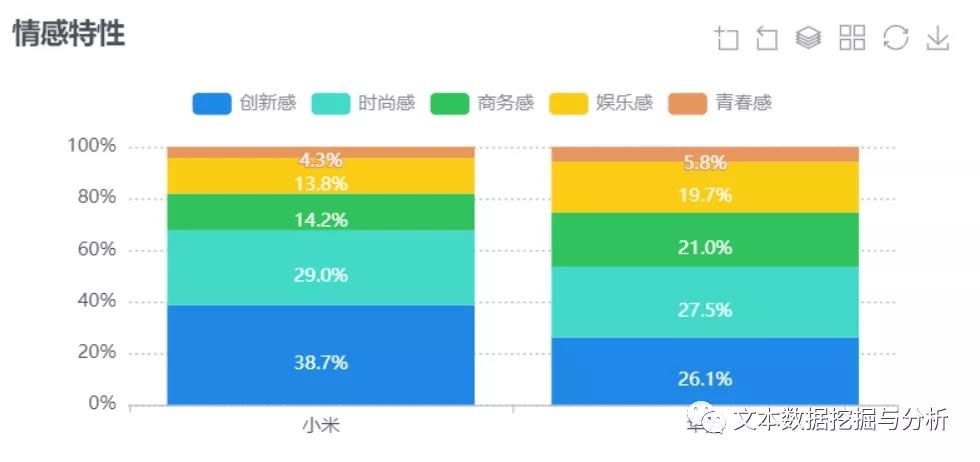
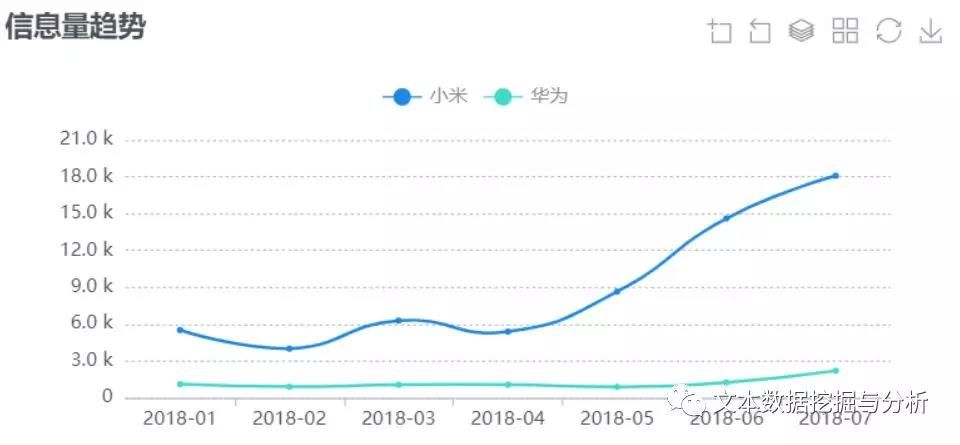
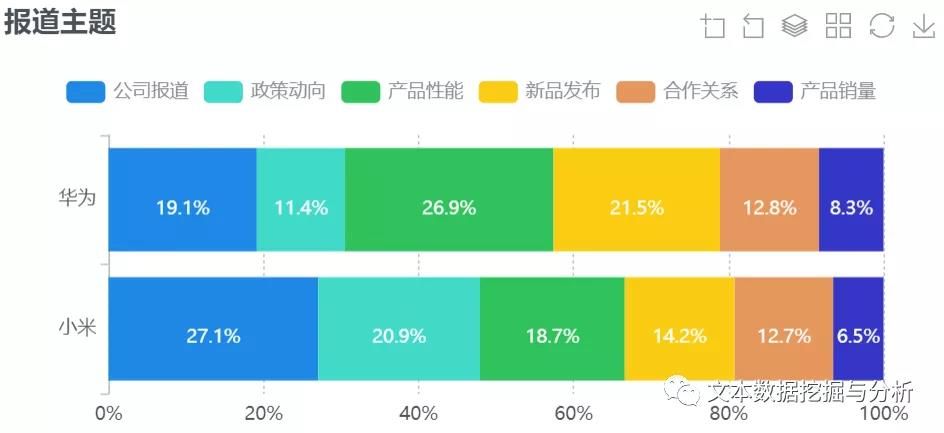


 温馨提示:
温馨提示: