问卷调查的开放题数据可怎样有效处理?
-
概要:DiVoMine是内容分析法为设计核心的在线数据挖掘与分析平台,用户们有没有想过可用于调查问卷中开放式问题的分析呢?其实DiVoMiner可以高效且科学的处理开放式问题答案文本数据的编码与统计分析,究竟是什么原理,又是怎么做呢,小编在本文中一一道来。
一. 什么是开放式问题?
一般而言调查问卷问题依据不同的研究需求,可分为封闭式问题和开放式问题。简单来说:封闭式问题=有限制答案
开放式问题=无限制答案

那么在实际应用中,封闭式问题受访者需要根据提供的选项来作答,优点是答案往往非常清晰,可以更好的实现调查研究测量的目标。缺点是在有些场景中,例如研究者要知道受访者行为、态度等背后所隐藏的原因和逻辑过程以及受访者常用的词汇,可以作为反映个人价值观、教育程度、知识水平等问题,封闭式问题并不能满足这一需求。
开放式问题受访者可以根据自己的主观想法作答,优点是为研究者搜集新的想法,对受访者实际情况有更多了解。缺点是所得到的答案未做结构化标准化处理,不易作统计分析;或者由于受访者的语言技能,答案缺乏信度,回答问卷难度增大。
二. 为什么用内容分析法?
由上可见,上述的两种方法都有着各自的优劣势,但想让开放式问题从定性的见解转化为统计性的见解是一个较为头疼的问题——小编建议用内容分析法。内容分析法是一种以系统的、客观的 和定量的方式测量变量,其最终目的是以数字来精确地再现信息主体,其实现方式是将文本转换为数字。所以,内容分析法对于开放式问题数据分析最合适不过。三. DiVoMiner解决方案
为了让大家更加清楚的熟悉整个分析过程,小编根据DiVoMiner平台的流程,整理一套解决方案,供大家学习参考。
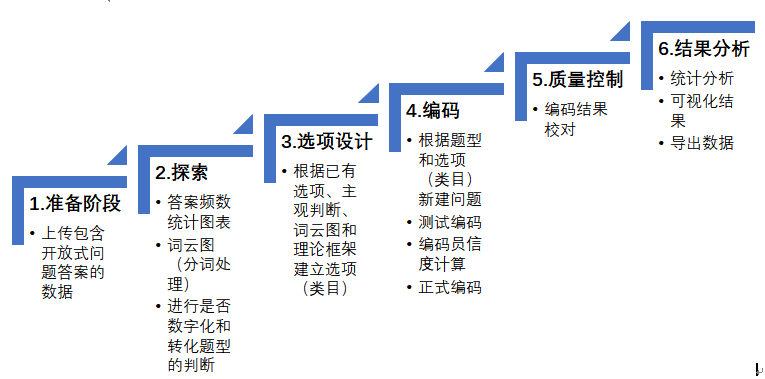
准备阶段(平台上完成)
首先确定开放式问题的答案并进行数据处理,建议将spss格式转化为excel格式,如果采用机器编码,只会针对标题或内容进行分析,因此表格建议至少包含以下内容:
其次,多个开放式问题的答案需分别建立数据子库。因为不同子库可能所对应的(类目)选项不同,后续数据探索、在线内容分析、统计分析及可视化等均可基于不同子库数据进行分析,而不会产生分析的混淆。如果想要详细了解步骤,可参考文章【DiVoMiner】三步将研究数据“装”进我的数据库,就是这么简单探索阶段(平台上完成)
在完成数据建库后,利用网络挖掘或算法模型等机器分析方法快速分析数据,查看数据结果。可在【统计分析】中选择【新建图表】-【词云图】,将自定义的答案变量进行聚合和分词分析。下图我们用示例做了一个分词词云图,可以看到开放题答案中主要内容可归纳为:价格、对巧克力的偏好、口味、品牌偏好等。

需要注意的是,建议在探索阶段,研究者根据答案的情况需要作出做两个判断:
A. 答案是否适合进行数字转化?
如果不适合数字转化,考虑转做质化分析。B. 答案适合编码为哪种题型?
DiVoMiner平台支持多种题型,但如果需要做量化分析,主要是考虑单选题和多选题。单选题结构比较简单,而多选题则可分为不定项多选和定项多选两类,在设计问题时需要不同处理方式。3.(类目)选项设计阶段(可与编码阶段合并完成)
编码类目是内容分析法的基础,在一定程度上,类目建构的质量决定了内容分析的成败和好坏。由于开放式问题是已经确定的,这里只需要由研究者设计编码类目的选项,由编码员阅读文本材料并进行编码或分类。编码类目表又叫编码簿,相当于问卷调查中的调查表,也就是说在这个阶段需要研究者做出问题的选项。有关选项设计有一些原则,可参考【DiVoMiner】建好编码类目,数据结果就完成一大半啦!从提高效率角度,小编认为可以从多个方式来进行:
• 挑选阅读部分答案进行主观经验判断;
• 词云图和理论框架形成(类目)选项;
• 如果是半开放式问题,可包含已有(类目)选项,因有受访者可能是对选项不理解所以选择其他,进行叙述性答案。
这里小编还要提醒用户,因为叙述性描述可能是从不同角度来考虑问题,每一个方面又会有多种有关的观点和事实,比如简单的问题,“您的职业?”,有可能是就业状态答案,有可能是所属行业,亦有可能是职位,因此需要根据调研的目的对有多方面属性的问题答案进行统一的规范,方便编码员的理解。
编码阶段(平台上完成)
这个阶段的工作较为繁琐,建议分为四步完成,也可根据实际情况进行:
A、新建问题
研究者需要根据题型和(类目)选项新建问题,也就是在平台左侧【类目管理】中选择【新建问题】。在这里小编强调下,DiVoMiner平台多选题的处理方法为二分法,也就是说,选中这个选项为1,没有就为0。
比如前面例子,为什么你不会购买XX品牌的巧克力?选项1:价格,选项2:口味,选项3:品牌偏好,选项4:不喜欢吃巧克力。如果答案是“价格太贵,口感不滑”,那么此受访者对应的答案是:1、1、0、0B、测试库
在完成【类目管理】之后,小编建议用户在正式开展编码之前,进行小范围的测试,以便对选项设计进行修正。详情可参考【DiVoMiner】一张图说清楚平台四个数据库的关系C、信度测试
信度测试是为了统一编码员的理解,减少差异性,如果研究者需要使用编码员间信度结果作为衡量标准,当信度结果达到一定水准时,才能够进入正式编码环节,可选用此方法。具体步骤可参考【DiVoMiner】有最好用的编码员间信度测试系统,不信?马上试一下D、编码
研究者对于答案编码可选择使用机器编码或人工编码,对于客观性较强的(类目)选项,比如人名、机构名等,可以交由机器判断,机器编码的准确性高,速度快,效率极高。对于主观性较强,需要编码员理解的(类目)选项,如情感态度,或者题目数量较少,建议进行人工编码。更多内容可参考【让研究更容易】如何结合机器与人工进行文本数据研究质量监控阶段(平台上完成)
对于质量控制,DiVoMiner提供实时数据监测功能,可在左侧栏【编码绩效】随时查看编码员工作绩效,在【编码结果】中快速查看已做编码的单变量频数结果,【质量监控】提供便捷的方式修正数据结果。结果分析阶段(平台上完成)
完成内容分析后,可进入数据分析环节。在平台上,可快速查看单变量的频数结果(【编码结果】页面),亦支持用户自制图表(【统计分析】页面),通过简单的拖拽式操作,快速生成图表,可调整可视化效果。如果需要下载数据,放回统计软件中进行分析,可在【质量监控】中选择【导出】,将可导出csv格式数据,需要注意的是【质量监控】对应的是数据子库,如果有多个数据子库,需要分别选择进行数据导出。
四. 小结
开放式问题可以带给你超乎预想的发现,不要随意浪费这些数据,还请通过科学严谨的流程进行分析,可能对研究做出重要的贡献。