【DiVoMiner®】手把手教您轻松完成复杂项目的研究
-
本期将手把手教大家如何在DiVoMiner
 上进行长时间跨度的大型研究项目,以及复杂研究目的、多面向研究问题的专题项目。
上进行长时间跨度的大型研究项目,以及复杂研究目的、多面向研究问题的专题项目。
温馨提示
在DiVoMiner平台上提供了一些研究案例,大家可以进入平台(进入:me.divominer.cn)随时查看数据、类目、编码结果、统计分析结果。
大家可以按照以下步骤开始您的研究!
让我们来看一下一个完整的大数据技术辅助在线内容分析法的流程:
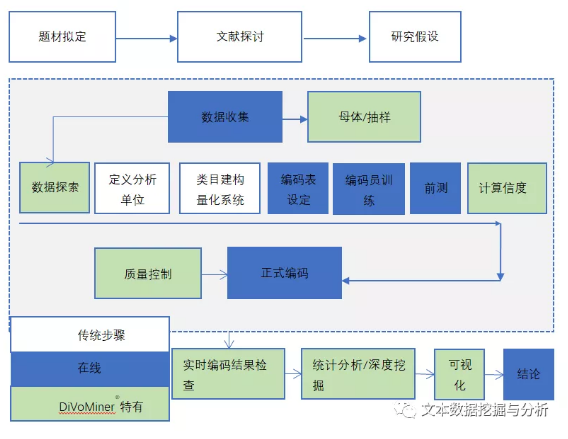
具体到一个研究议题上,基本的流程图如下:
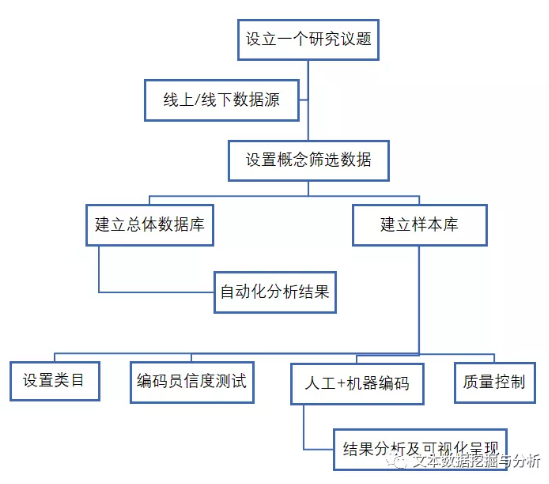
确定好研究议题后,总共需要以下四步:1
建立数据库
(点击查看☛三步将研究数据“装”进我的数据库,就是这么简单!)
2
建构类目
(点击查看☛建好编码类目,数据结果就完成一大半啦!)
3
编码
编码员信度测试
(点击查看☛有最好用的编码员间信度测试系统,不信?马上试一下!)
机器编码和人工编码
4
统计分析及可视化呈现
(点击查看☛轻松通过个性化词云图,探索海量数据,辅助建构研究类目!)确定研究议题
——媒介融合论述及发展趋势分析传媒业界及学术界对此议题所论述的焦点及异同之处,探讨未来媒介融合的发展趋势。
数据:过去六年新闻媒体及学术论文对媒介融合议题的论述及研究。
时间范围:2013年1月1日到2018年12月31日。
第一步
建立数据库数据库建立一般有两种方式,一种是线上采集数据,一种是将本地数据上载。
本研究分析了两部分的数据:
传媒业界的数据,采用了线上采集数据建立数据库的方式——汇集了两岸四地关于媒介融合的新闻报道,共计44,936篇。
学术界的数据,采用了上传本地文档到平台建立数据库的方式——汇集了来自中国知网核心期刊,且篇名中含有“媒介融合”的相关文献共计752篇。
●
线上采集数据小编以媒介融合的概念、性质、不同的表达方式等为核心,围绕媒介融合涉及到的核心关键词进行线上数据采集,建立新闻数据库。
关键词如下:
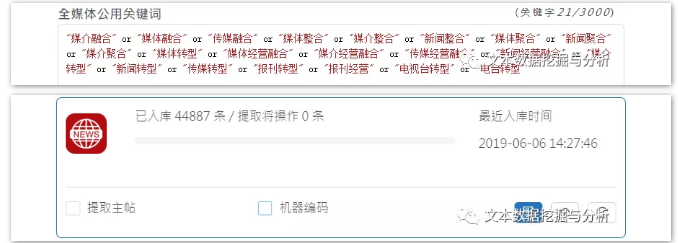
注意:线上采集数据建立数据库仅在机构版DiVoMiner
上提供,学习版和研究版DiVoMiner目前支持上传数据建立数据。更多请进入www.divominer.cn进一步了解。●
上传数据将线下的PDF格式的文本直接上载至平台中,建立媒介融合学术数据库。该些文本来自于中国知网中国期刊全文数据库的核心期刊,篇名中含有关键词“媒介融合”的学术文献。

第二步
依据研究目的建构类目根据我们这个案例的研究目的,我们需要做的类目集中在态度、事件中涉及的人物、虐童行为和公关行为四个方面,因而类目设置围绕这四个方面进行展开。
1
媒介融合概念
2
融合形式
3
提及传统媒体类型
4
提及新媒体类型
5
融合趋势
5.1技术发展趋势
5.2内容生产发展趋势
5.3媒介融合的应用趋势
5.4产业格局融合
5.5政策法规完善趋势
6
学术界研究的学科类别
7
媒体来源地区
8
媒介融合涉及的新闻报道主题第三步
开始编码编码主要有两种形式:机器编码和人工编码
机器编码:对于一些客观性题目可以优先选择机器编码,快速高效完成海量数据的编码。
在这个研究中,由于新闻报道数据量之庞大,为节省小编势单力薄的人力,当然是选择机器编码,一键触发机器编码,四万多条数据,十分钟之内完成。接下来小编要去听听音乐放松一下。
两首歌的时间后……
新闻媒体数据库已完成了编码。人工编码:对于一些主观性比较强的题目选择人工编码,可以确保准确度,另外也可以对机器编码结果进行再次校正。
学术文献数据库因为是PDF格式的文本,加上学术文献内容较为复杂,为了确保研究结果的高度准备,小编需要人工编码,因而叫上了几个同学加入了文献阅读和编码的队伍。
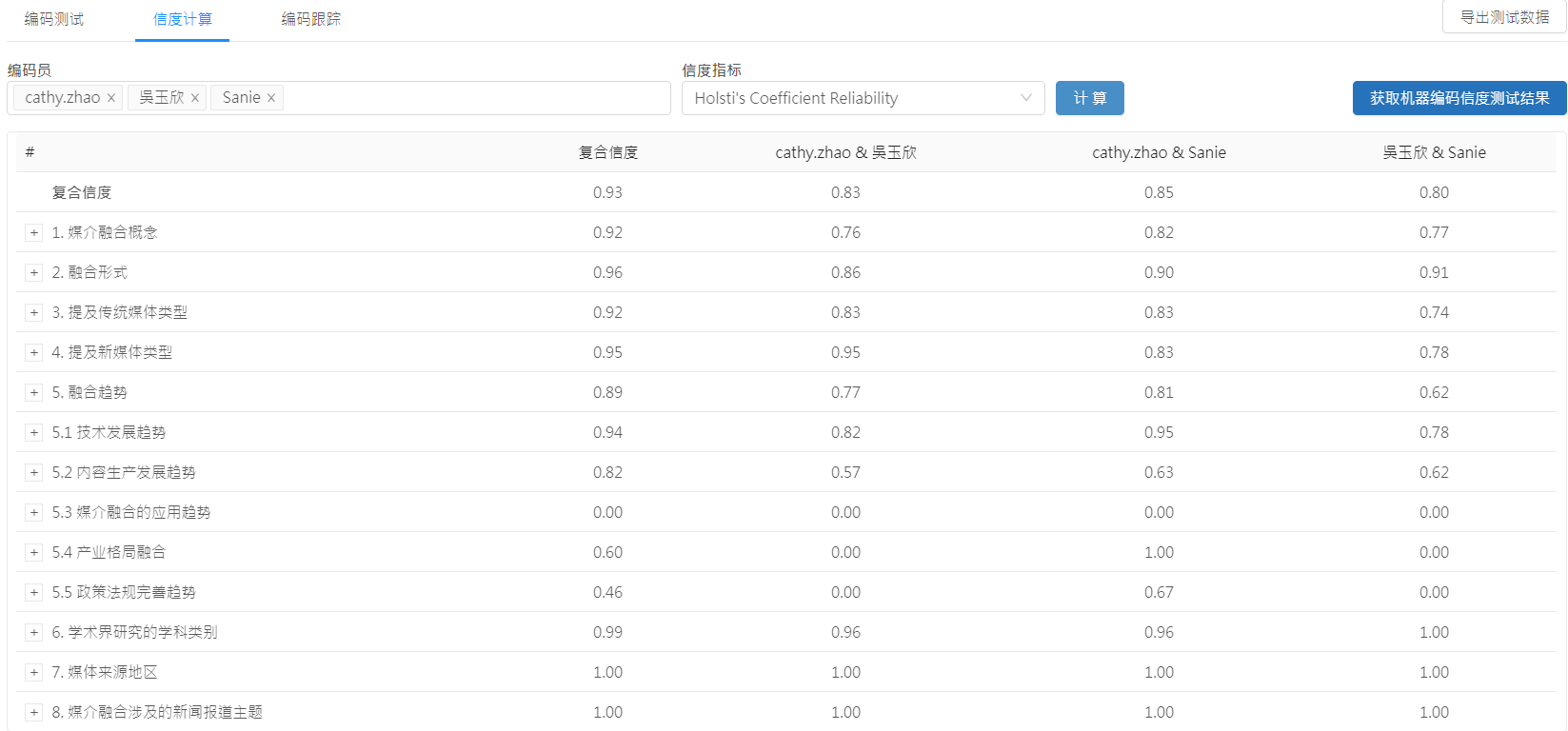
等一等,为了确保编码质量,
先进行信度测试。●
先建个测试库,开始编码。
●
如果运用机器编码,则执行机器编码的信度测试。
●
信度系数计算只需要选择编码员和信度系数计算方法即可,信度报告立即产生。针对结果偏低的题目可以有针对性的进行编码员培训,再重新进行信度测试编码。直至信度结果达标。
第四步
对编码结果进行统计分析和可视化呈现有了编码结果,统计分析就更加轻松了!打开Excel还是SPSS?通通不用!直接在平台上拖拽变量就可以!您想要的单变量、多变量、卡方、时间线、词云图……应有尽有,至少完成一个这样的研究是绰绰有余。
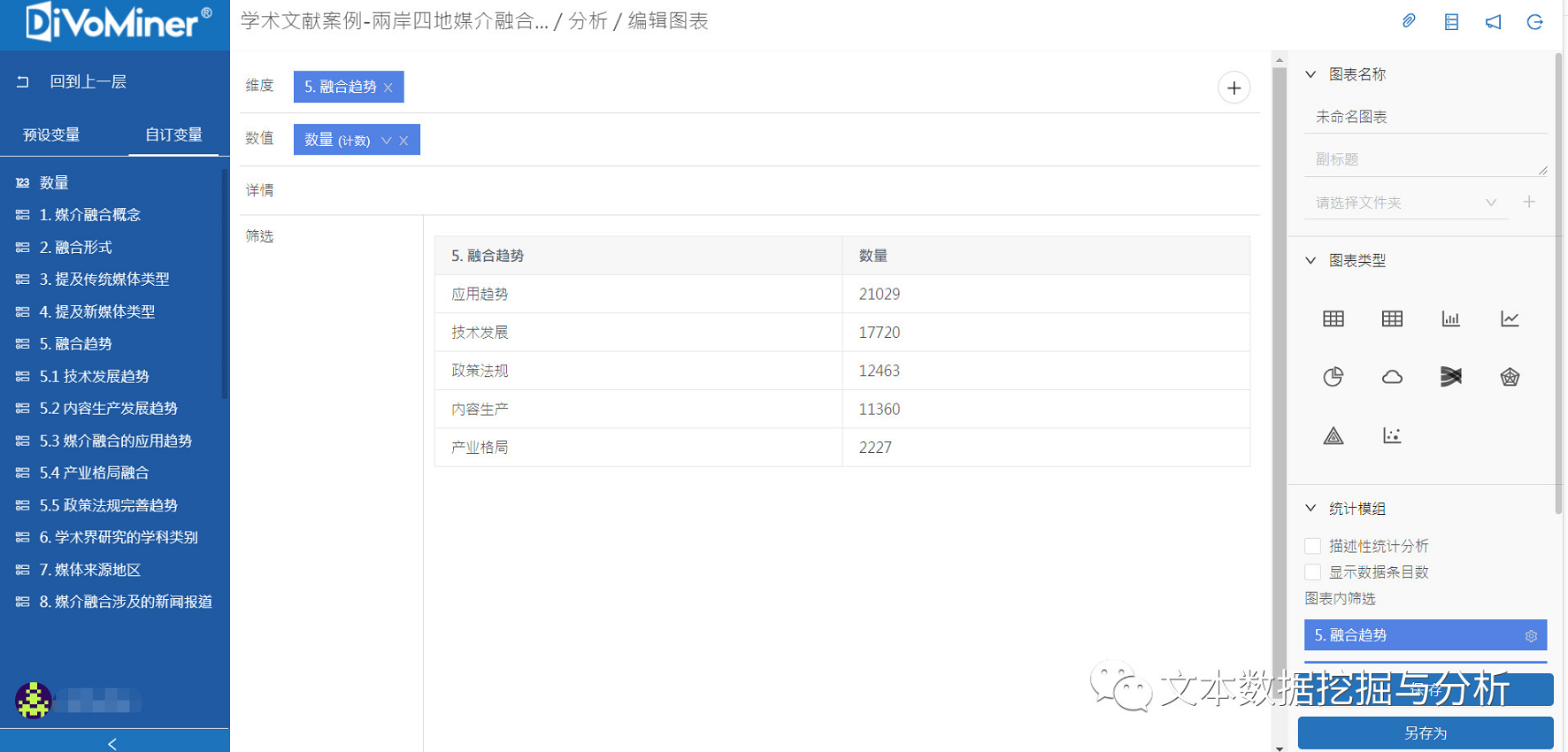
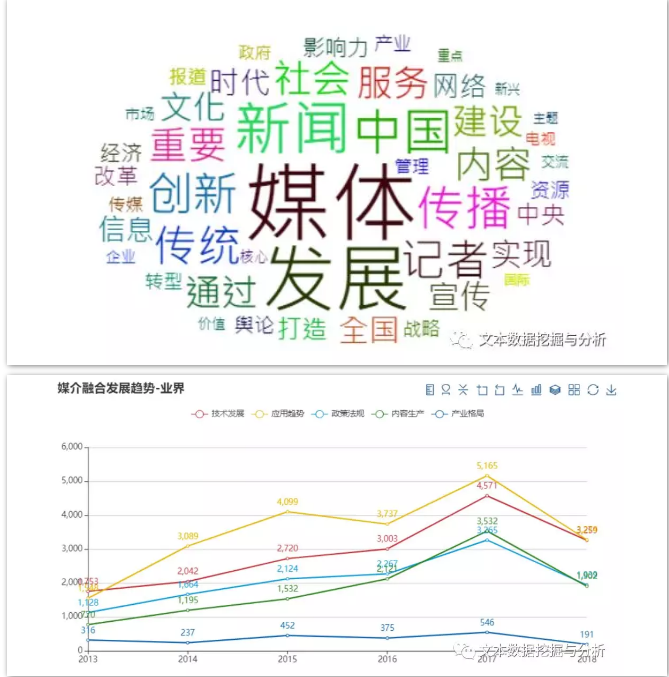
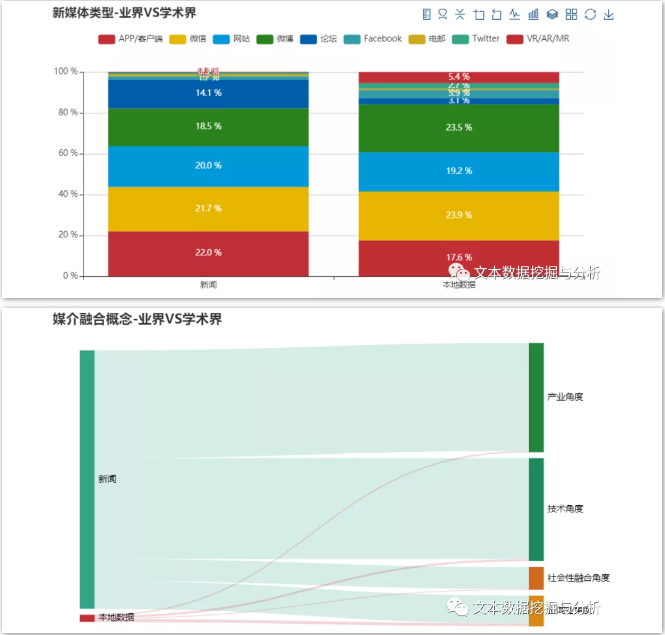
看图

小编仅选取部分分析结果给大家做示范作用,若大家有兴趣可以自己尝试哦!
进入me.divominer.cn,
开始你的研究吧!
最后一步
写!
统计分析结果的这些可视化图都已经出来了,至于图表中的结果数据的解读和描述,点击一下你想要解读的数据,自动追踪回溯到原文,一边查看一边思考一边解读。嗯~
一篇有洞察的研究就这样高效完成了!
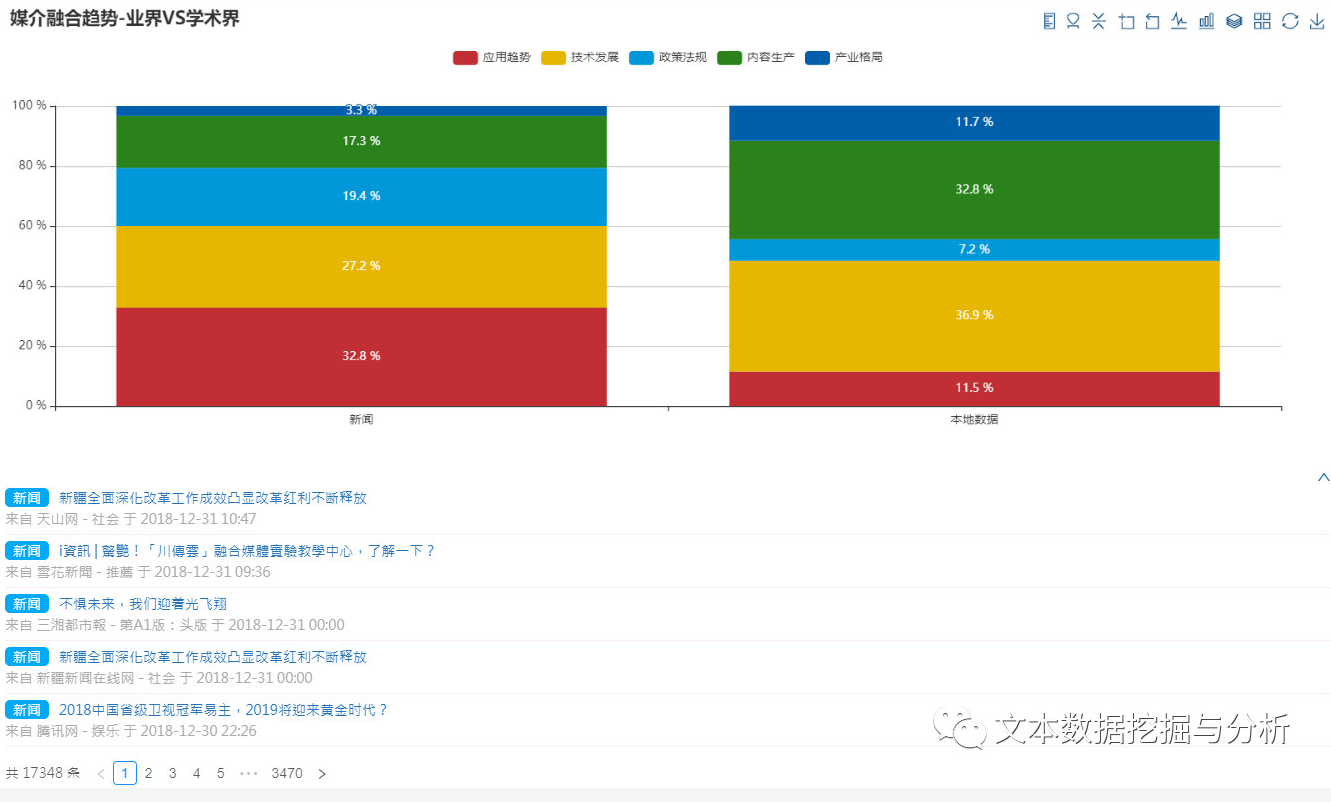
对于统计分析结果,小编在这里就不给大家做详尽解读了,大家可以自己尝试来做一下这个研究,看看不同的类目、不同的研究内容可以出来什么样的分析结果出来。