DiVoMiner®设计理念及操作流程
-
DiVoMiner
 是一个基于云计算的文本大数据挖掘及分析平台,以大数据技术辅助在线内容分析法为设计核心,利用机器学习及人工校正编码方式,一站式完成内容分析法的全部流程,包括建立数据库、抽样、编码员间信度测试、在线内容编码、质量控制、统计分析和结果可视化等流程。提供灵活而强大的团队研究执行及管理功能,是市场上唯一一个兼具实用性和学术性要求的网络挖掘和文本分析平台。
是一个基于云计算的文本大数据挖掘及分析平台,以大数据技术辅助在线内容分析法为设计核心,利用机器学习及人工校正编码方式,一站式完成内容分析法的全部流程,包括建立数据库、抽样、编码员间信度测试、在线内容编码、质量控制、统计分析和结果可视化等流程。提供灵活而强大的团队研究执行及管理功能,是市场上唯一一个兼具实用性和学术性要求的网络挖掘和文本分析平台。
DiVoMiner平台的设计理念及方法论核心是大数据技术辅助在线内容分析法。大数据背景下,网络数据体量庞大且结构繁杂,分析难度较大,因此,研究之初,需要将海量数据搜集结构化,包括线上和线下数据,以此形成数据研究的基础——数据库。其次,利用计算机运算能力的优势,使用网络挖掘、机器学习以及社会网络分析等手段,快速得出初步数据结果,可以据此了解数据概况和部分细节,寻找未知的规则。然而,在大部分的研究场景下,仅仅使用机器分析可能未必能够达到足够的研究深度,因此,需要进一步在已知规则中深度探索研究意义及洞察,这时,可以使用在线内容分析,通过人工编码、机器编码、机器学习编码,结合人的智慧,完成深度挖掘。运用数据,得出价值。
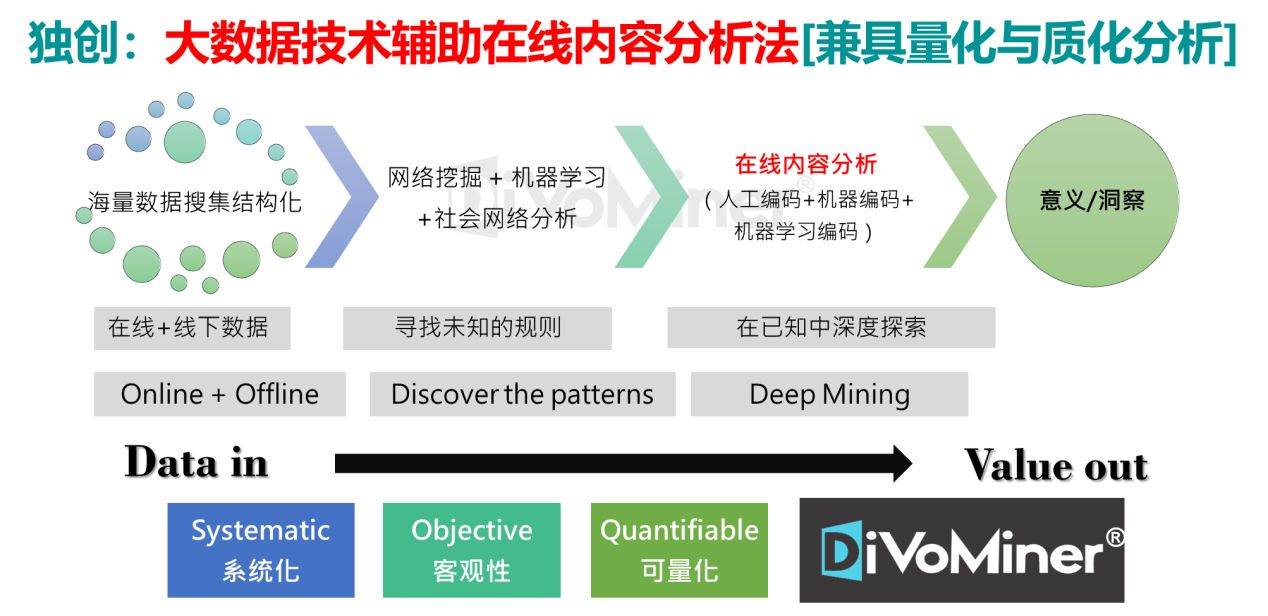
DiVoMiner将研究方法中强调的系统化、客观性和可量化的特点贯穿始终。落实到操作流程中,可区分为准备阶段、探索、在线内容分析(编码及质量控制)和结果呈现四大部分。
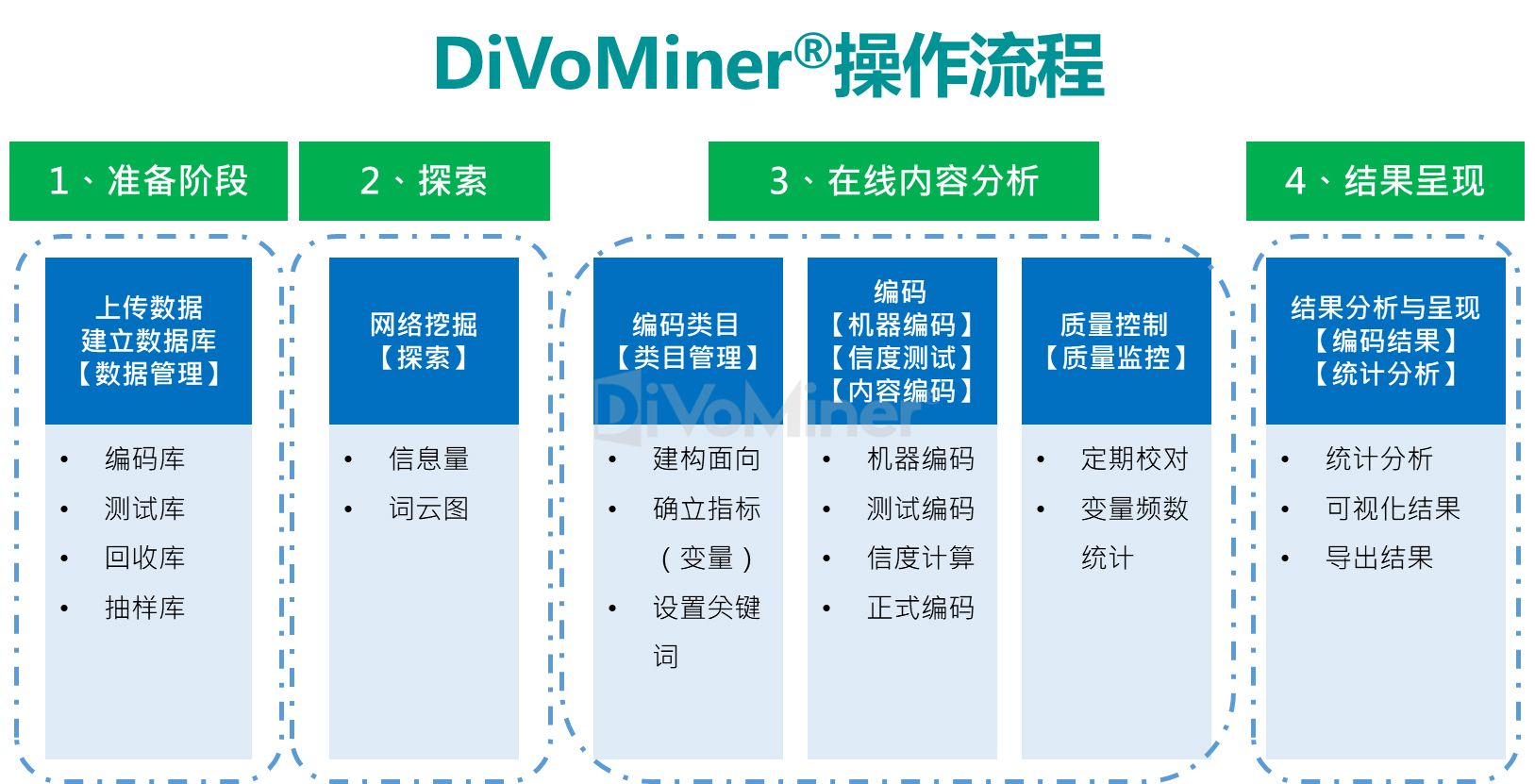
1、 准备阶段:确定不同类型的数据来源,分别建立数据子库,例如,历史文献数据与社交媒体数据格式有所不同;不同的社交媒体数据类型有所不同;将格式不同的数据类型分门别类上传至对应的数据子库,完成建库过程。
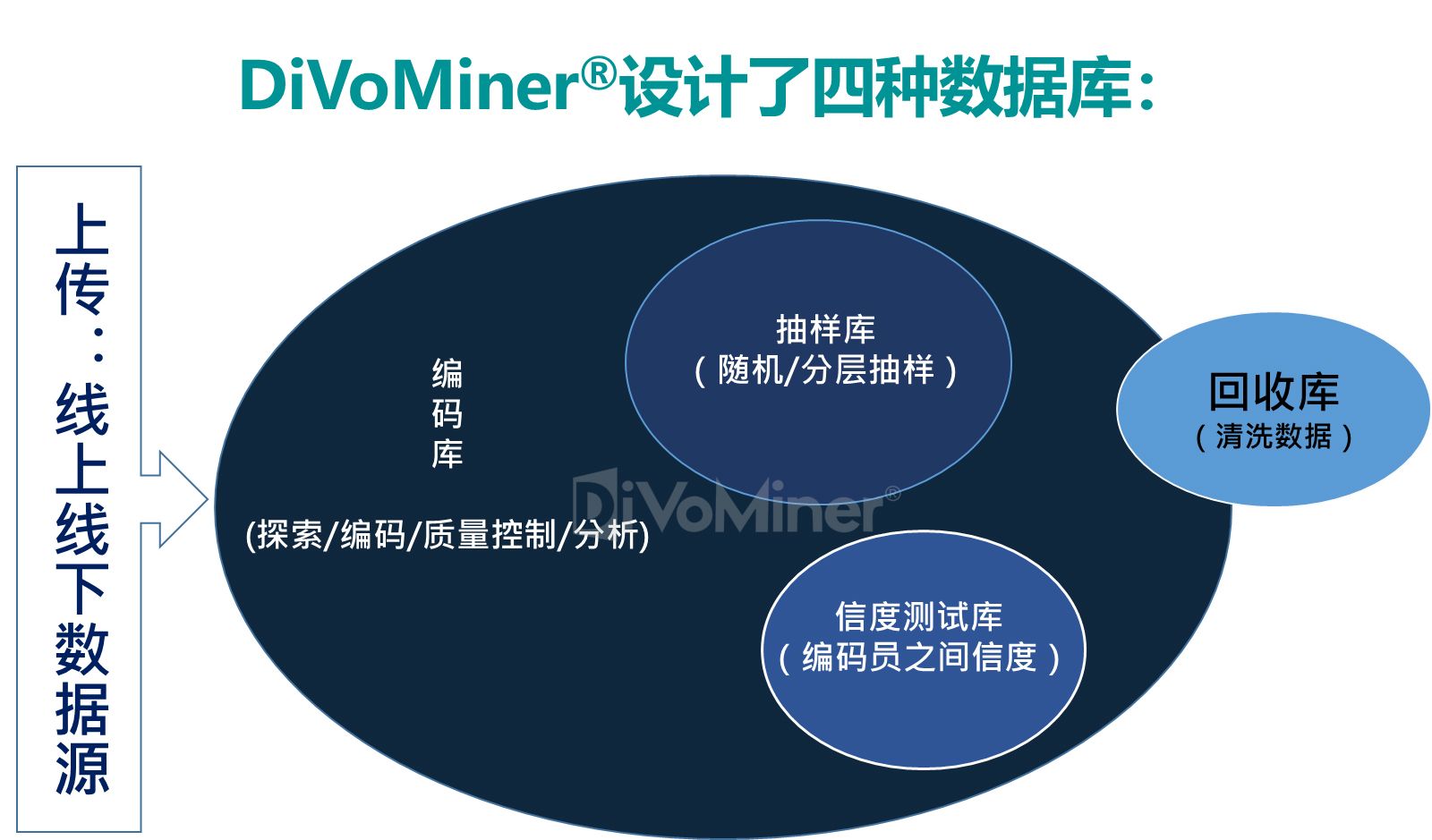
DiVoMiner针对数据库的不同功能需求设计了四种类型数据库。用户上传数据至编码库,不同格式的数据放至不同的子库,不同子库之间字段可通用。后续数据探索、在线内容分析、统计分析及可视化等均基于编码库中数据进行分析。清洗数据后删除的数据放入回收库。
测试库设计用于测试编码(前测编码),要求编码员对相同的数据进行测试编码,计算编码员之间信度,在信度达到可接受的一致性水平后,开始正式人工编码。
如需要进行数据抽样,可建立抽样库,以随机或其他方式抽取部分数据,完成研究项目。
2、 探索:完成数据建库后,利用网络挖掘或算法模型等机器分析方法快速分析数据,查看数据结果。平台上可查询整体数据的自动化信息量趋势和词云图。
3、 在线内容分析:编码类目是内容分析法的基础,在一定程度上,类目建构的质量决定了内容分析的成败和好坏。由研究者设计编码类目,由编码员阅读文本材料并进行编码或分类。编码类目表又叫编码簿,相当于问卷调查中的调查表。
对于内容编码可使用机器编码或人工编码,对于客观性较强的类目,比如人名、机构名等,可以交由机器判断,机器编码的准确性高,速度快,效率极高。对于主观性较强的类目,比如意向态度,机器判断的准确度可能较为欠缺,建议进行人工编码。
对于质量控制,DiVoMiner提供实时数据监测功能,可随时查看编码员工作绩效以及编码结果,提供便捷的方式修正数据结果。
4、 结果呈现:完成内容分析后,可进入数据分析环节。在平台上,可快速查看单变量的频数结果(【编码结果】页面),亦支持用户自制图表(【统计分析】页面),通过简单的拖拽式操作,快速生成图表,可调整可视化效果,满足用户需求。
-
